
A wiki that maintains itself: an LLM knowledge layer in production
I gave a model the tools a coding agent has, pointed it at a marketing team's knowledge base, and automated its upkeep. The hard part was never the AI. It was deciding what the AI was responsible for.

The first version of this system was easy to explain, which should have been the warning. It was a “second brain,” an MCP tool that read files out of a Google Drive and answered questions about them. Ask it something, it pulled a few documents into the prompt, the model answered from whatever it grabbed. People called it an intelligence layer. It was a search box with a personality.
What it didn’t do was the thing that would have made it valuable: get better over time. Every question started from zero. Nothing it learned on Monday was there on Tuesday. Knowledge didn’t accumulate, it just got re-fetched and re-derived, over and over, from the same flat pile of files

Then Karpathy posted a gist that named the thing I was missing. Instead of retrieving documents at query time, he argued, an LLM should incrementally build and maintain a persistent wiki, a structured, interlinked set of markdown pages that sits between the user and the raw sources. The knowledge is compiled once and then kept current, not re-derived on every query. The wiki is a compounding artifact. The model’s job isn’t to answer from scratch each time. It’s to do the bookkeeping: summarize new sources into pages, cross-reference them, flag contradictions, keep the whole thing current.
That reframed the entire project. The work wasn’t a better retriever. It was an intelligence layer that accumulates, and a system that keeps that layer healthy without me babysitting it. This article is a postmortem of the second version I built on that idea, the one I named codex, and the decisions that the gist leaves out. It’s running in production for a marketing team. And the most important section in here isn’t about the architecture at all. It’s about what I had to argue the system was not for.
What codex is
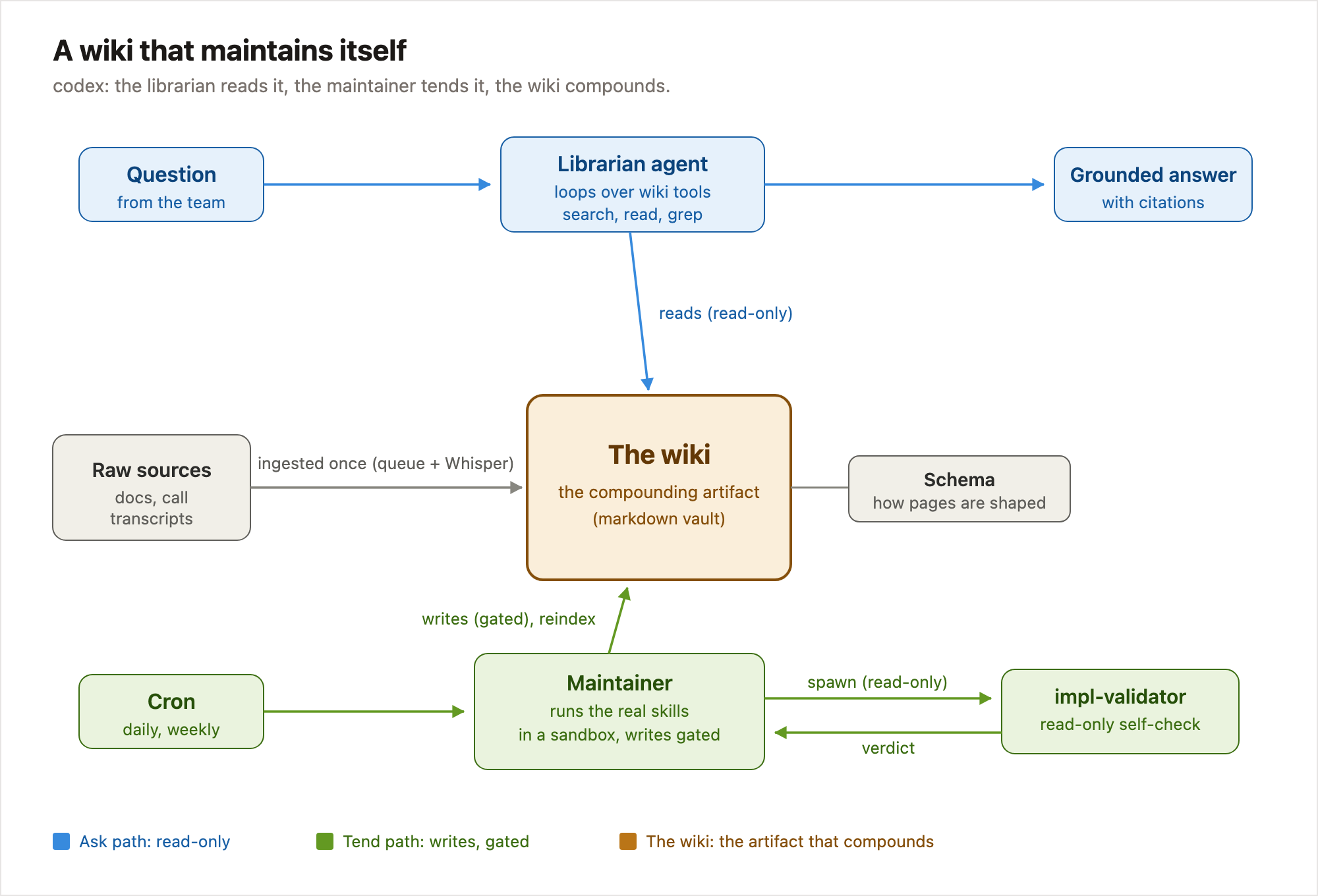
Codex is a multi-wiki knowledge platform: a FastAPI service with a LangGraph agent inside it, backed by Postgres, deployed on Azure. It maps directly onto the three layers from Karpathy’s gist.
Raw sources. The immutable inputs. Documents, plus call transcripts run through Whisper. These get ingested, never queried directly.
The wiki. An Obsidian-style vault of markdown pages, one folder structure per domain. This is the compounding artifact. There are multiple live wikis today, but today we’re discussing the marketing team’s, which I’ll call cmo.
The schema. The rules for how the wiki is shaped and maintained, written as skill files the way Karpathy uses a CLAUDE.md.
Three things talk to it. A /chat endpoint where you ask the librarian a question. An MCP server, so agents like Claude Code or Cursor can call the librarian directly as a tool. And a scheduled maintainer that wakes up on a cron and edits the wiki on its own. The decisions below follow the order a piece of knowledge moves through the system: how a question gets answered, how the wiki gets maintained, how the agent is contained while it does that, how its output earns trust, and how raw sources get in at all.
Decision 1: The librarian is an agent that searches, not a pipeline that retrieves
The V1 of this system was simple to describe, which should have been the warning. A question came in, the tool pulled some files out of Google Drive, stuffed them into the prompt, and the model answered from whatever it happened to grab. One retrieval, one answer. When it was right it was because the answer lived in the first thing it pulled. When it was wrong it was confidently wrong, because it never knew there was a second thing to look at.
That shape has a name now, retrieve-then-answer, and its problem is that it commits to how much looking a question needs before it has read a single word. “What is the selfish-viewer principle?” needs one good search. “How does the selfish-viewer principle apply to a webinar funnel?” needs that page, the page on webinar funnels, and the judgment to notice the vault has no page connecting them and say so. A fixed pipeline serves the first question and quietly fails the second, and from the outside both answers look equally fluent.
So in codex the librarian isn’t a pipeline. It’s an agent with the same kind of tools a coding assistant has, scoped to one wiki: full-text search, read a page, list a folder, grep for an exact string. It runs them in a loop and decides for itself when it has enough.
for iterations in range(1, recursion_limit + 1):
ai = self._invoke(history)
history.append(ai)
calls = ai.tool_calls or []
if not calls: # the model stopped asking, so it's ready to answer
final_ai = ai
break
for tc in calls:
result = tools_by_name[tc.name].invoke(tc.args)
history.append(ToolMessage(content=str(result), tool_call_id=tc.id))There’s no router deciding the question’s type up front, and no fixed number of retrievals. The model searches, reads what came back, and either answers or searches again with a better query. The system prompt pushes it the way I’d push a junior researcher: search first, don’t answer from a single hit, and if a page links to another page that looks relevant, go read that one too. That last instruction is the whole point of Karpathy’s wiki. The value is in the links between pages, and you only get it if something follows them. A retrieve-then-answer system never follows a link. It can’t, because it already used its one move.
Every claim the librarian ends up making is tagged with the page it came from, and the system tracks the pages the agent actually read during the loop rather than the ones it later claims to have read. A reader can follow any sentence back to the shelf it came off.
The cost is real and I pay it on every request. An agentic loop is slower and more expensive than a single retrieval, three or four model calls where the old system made one, with a worst case bounded only by a recursion limit. It’s also harder to reason about, because two identical questions can take different paths. I decided that was the right trade for a librarian specifically. The job is to be right about what’s in the wiki and clear about what isn’t, and you cannot be reliably clear about a gap you never searched for. A pipeline optimizes for the median question. A librarian has to survive the hard one.
The one-sentence test: how much looking a question needs isn’t knowable until you’ve read the first result, so the model has to drive the search instead of a fixed route deciding for it.
Decision 2: The wiki maintains itself by running the skills I already had, not code I wrote
Karpathy’s gist is one paragraph of architecture and one hard part. The architecture is the three layers: raw sources, a wiki, a schema. The hard part is the verb. The wiki has to be maintained: kept current as sources arrive, cross-linked, deduplicated, checked for contradictions. That maintenance is the whole reason the thing compounds instead of rotting. A wiki nobody tends is just a folder of stale markdown.
So the real question wasn’t how to store the wiki. It was who does the tending, and how.
The obvious answer was to write it. I knew what daily maintenance looked like, because I’d been doing it by hand in Claude Code for weeks: run the daily-update skill, run a lint pass, let a synthesis skill propose new connecting pages. Those skills already existed, a library of SKILL.md files that encode how to keep a vault healthy. I could read them, understand the steps, and reimplement those steps in Python as proper functions with tests.
I didn’t, and not reimplementing them is the decision.
The moment you rewrite a skill as native code, you have two versions of the same procedure: the SKILL.md I run by hand, and the Python I run on the server. They start identical and immediately drift. I tune the skill in Claude Code, the server keeps running last month’s logic. Worse, the skills aren’t deterministic procedures I can transcribe cleanly. They’re instructions written for a model to interpret, full of judgment calls about what counts as a contradiction or a synthesis-worthy pair. Freezing that judgment into Python throws away the part that made the skill good.
So the maintainer runs the skill itself. A skill is just a markdown file of plain-language instructions for a model: read the manifest, reconcile the index, regenerate the summary page, log what changed. On my laptop I run one by hand in Claude Code and the model carries out those steps with its file tools. On the server, codex does the same thing on a schedule, with no human in the room and the same tools pointed at one wiki. The cron doesn’t run maintenance code I wrote. It runs a model following the same recipe I’d follow myself.
The skills were written for that laptop, so a handful of their instructions point at things the server doesn’t have: where the vault lives, where they keep notes between runs, and one step that hands the finished work to a reviewer. I could have edited each skill to match the server, but that’s a fork, and a fork drifts from the version I run by hand. So I leave the skills untouched and prepend a short note that tells the model how to read those instructions here. The files stay identical to the ones on my laptop. The note is the adapter.
That reviewer step is worth dwelling on, because it’s where I cut a corner and had to come back for it. The daily skill ends by handing its work to a second agent, impl-validator, with a checklist: is the timestamp fresh, does the summary page carry today’s date, did the index reconcile cleanly. My first version had no way to run a second agent, so it skipped the step and noted that it would have. Which meant the daily maintenance ran with its own self-check switched off, every single day. So I built it in. The maintenance agent can now spawn that reviewer as a second pass, one that reads everything the run just wrote and is allowed to change none of it. The daily update grades itself before I ever look at it.
Autonomy this real is why writing is a gate rather than a request. An unattended model editing the company’s knowledge base is the scary mode, so by default a run can read and plan but not write. Writing is something I switch on deliberately, and it’s enforced in the code, not asked for in the prompt. Every run leaves a report of what it changed, or would have changed, so I can read the diff before I trust the next one with the keys.
What this buys is the thing Karpathy’s gist is really about. The wiki isn’t something I generated once and left to rot. Every morning a model reads the sources that arrived, folds them into the pages that already exist, and flags what doesn’t fit, using the same skills and the same judgment I’d apply by hand, just without waiting for me to open a terminal.
Decision 3: An autonomous agent gets a sandbox, not the real vault
Decision 2 settled when the maintainer is allowed to write. This one is about where, and it turns out to be the harder question, because “where” has two failure modes that look nothing alike.
The first is the obvious one. The model drives a loop of file tools, and a tool call is just a string it generated. Nothing stops it from emitting read_page or a Bash command that walks out of the wiki and into the rest of the container. I’m running a non-deterministic process with filesystem access on a server that holds more than one tenant’s data. The boundary can’t be a polite instruction in the prompt. It has to be code the model can’t talk its way past.
So every path a tool touches goes through one resolver, and the resolver’s only job is to refuse anything that escapes the wiki root.
def resolve(self, path, *, allow_state=True):
...
target = (p if p.is_absolute() else (self.root / p)).resolve()
if _is_within(target, self.root.resolve()):
return target
if allow_state and _is_within(target, self.state_root.resolve()):
return target
raise SandboxViolation(
f"path escapes sandbox: {path!r} -> {target}\n"
f" allowed roots: {self.root}, {self.state_root}"
)Two roots are allowed and no others: the wiki itself, and a scoped state directory where skills keep their bookkeeping (the $STATE_DIR/ I substituted into the skill instructions in the last decision). Everything resolves to an absolute path first, then gets checked for containment, so the clever escapes (symlinks, .. chains, an absolute path that happens to start with the right prefix) all collapse to a real location before the check runs. A path that lands outside both roots doesn’t get a careful error and a retry. It raises, and the model sees the violation as a tool result.
The second failure mode is the one I didn’t see coming. Even when the agent stays inside the vault and writes exactly what it should, a maintenance run is not atomic. It’s dozens of edits across many pages over a minute or two of model time. If it writes those directly into the live wiki and then fails halfway, say it hits its recursion limit, or the model refuses, or the container recycles, I’m left with a vault that’s half-updated and has no record of which half. The thing I built to keep the knowledge layer healthy would be the thing most likely to corrupt it.
So a writing run never touches the live vault. It copies the wiki into a scratch directory, lets the agent make its mess there, and only syncs the result back when the run finishes cleanly.
def __enter__(self):
if self._sync and self._sync.is_enabled():
if self.read_only:
# The cache directory IS the sandbox root. No copy.
self.root = self._sync.download_wiki_to_scratch(
self.wiki_name, Path("/dev/null"), read_only=True)
else:
self._temp_dir = tempfile.mkdtemp(prefix=f"codex_jit_{self.wiki_name}_")
self.root = self._sync.download_wiki_to_scratch(
self.wiki_name, Path(self._temp_dir), read_only=False)
return self
def __exit__(self, *exc):
if self._sync and self._sync.is_enabled() and not self.read_only and self._temp_dir:
self._sync.sync_scratch_to_azure(self.wiki_name, self.root)
shutil.rmtree(self._temp_dir, ignore_errors=True)A failed run leaves the scratch copy unsynced and the live wiki untouched. That’s the behavior I want: the worst case of an unattended agent is wasted compute, not a damaged vault.
But notice the branch at the top, because that’s where I got it wrong first. I originally copied the vault for every request, reads included. It was uniform and it felt safe. It was also the single biggest source of latency between a question and its first token. Chat is read-only, it never writes a byte, and I was making it wait on a full copy of the wiki before it could search anything. The copy was buying isolation that a read doesn’t need.
So read-only requests, chat and the reindex that rebuilds the search index, skip the copy entirely and point straight at the cached vault. The isolation copy now exists only for the runs that actually mutate, which are the only runs that can be left half-finished. Same boundary, paid for only when it does something.
The one-sentence version is the test I keep coming back to: an autonomous agent can read the whole wiki and damage none of it, because it writes into a copy and the live vault only ever sees a run that finished.
Decision 4: The answers have to be trustworthy, sound like the team, and admit when the model can’t help
A knowledge layer is only as good as your willingness to act on what it says. Three smaller decisions exist purely to make the output trustworthy, and they’re worth pulling out because each one started as a bug.
Answers cite their sources. Every claim the librarian makes is tagged with the page it came from, written as [[page#section]], and the system tracks which pages the agent actually read during its loop, not which ones it claims to have read. A reader can follow any sentence back to the page that produced it. This is the difference between a librarian and a confident stranger: the librarian shows you the shelf.
The model has to refuse out loud, not silently. This one I learned the hard way. I run different models for different jobs to manage cost, and one of the cheaper ones, a safety-tuned model, periodically declines to do work it’s perfectly capable of. It doesn’t fail with an error. It comes back with a polite refusal, sometimes in Chinese: 你好,我无法给到相关内容, which translates to “Hello, I cannot give you relevant content.” Zero tool calls, a twenty-character reply, and from the outside it looks like the wiki simply had nothing to say. The failure was invisible, which made it the worst kind.
So there’s a small, deterministic detector whose only job is to recognize a refusal masquerading as an answer.
def looks_like_refusal(final_message, *, writes_made=0, sources_found=0, tool_calls_made=0):
msg = (final_message or "").strip()
if msg and _has_cjk(msg):
return True, "CJK characters in response (refusal signature)"
if not msg and tool_calls_made == 0:
return True, "empty response with no tool work"
if len(msg) < 200 and any(p in msg.lower() for p in _ENGLISH_REFUSAL_PATTERNS):
return True, "english refusal pattern"
# did real tool work but wrote nothing and said almost nothing
if sources_found == 0 and writes_made == 0 and tool_calls_made >= 3 and len(msg) < 100:
return True, "zero output from real tool work"
return False, "" When it fires, the same work re-runs once on a different model that isn’t subject to the same bias. It’s a pure function, it’s deterministic, and it’s covered by tests, because the one thing I won’t tolerate is the system going quiet on a question it could have answered. A librarian that says “not in here” is fine. A librarian that pretends “not in here” is a liability.
Drafted copy has to sound human. The marketing team uses the librarian to draft real copy: emails, landing pages, ad scripts. A model writing marketing copy has a tell, several of them, and they’re instantly recognizable. So before the agent returns any drafted copy, it’s required to pass it through a humanizer tool that runs a long rule set against it, stripping the filler phrases, the hollow intensifiers, the parallelism that simulates thoroughness, the “in today’s landscape” openers, then rebuilding the rhythm. The whole point is a little self-aware: the system whose job includes writing copy is forbidden from sounding like a system wrote it. It runs the same humanizer ruleset I’d apply by hand, on every draft, automatically.
The one-sentence test for this whole layer: the librarian has to be checkable, has to fail loudly, and has to not embarrass the team, and none of those are things you get for free from “call the model.”
Decision 5: Raw sources get in through a durable queue, because the obvious way melted the container
The compounding wiki only compounds if new sources actually make it in, and ingestion is heavier than it looks. A single call recording means transcription through Whisper, then a model pass to turn the transcript into wiki pages. The first version of this was the obvious one: the HTTP handler accepted an upload and spawned a background thread to process it. Fire and forget.
It worked for one file. Then someone bulk-submitted, and the handler cheerfully forked a hundred background threads, each trying to run Whisper at once, and the container ran out of memory and died. The naive design had no notion of “too much at once” because each request only knew about itself.
So ingestion is now a proper queue. Jobs are written to Postgres, which is the durable state, and a single worker thread pulls them one at a time.
HTTP handler: Worker thread:
stage file to blob while True:
INSERT into ingest_jobs job = store.claim_next(worker_id)
put(job_id) on the queue if job is None: queue.get() # block until woken
return {job_id} run_ingest(job)
mark_done(job_id, report)The in-memory queue is just a doorbell. The truth lives in Postgres, and that’s what makes it survive a crash. If the container recycles mid-ingest, the worker reloads the queued rows on boot, and any job that was running when the lights went out gets marked failed with reason=interrupted, so I can decide whether to retry rather than discovering a half-ingested source weeks later. One worker by default, because the bottleneck is the model and the GPU, not the queue. The decision here is unglamorous and I think it’s the most broadly useful one in the whole system: the moment an LLM operation is expensive and triggered by users, “spawn a thread” is a memory leak with good intentions. Give it a queue and a single worker, and let backpressure be a feature instead of an outage.
What it’s for, and what it isn’t
I want to be precise about what this system does, because the most expensive misunderstanding in AI right now is the one I had to argue against in my own company.
The moment came as a question from the CEO, and I’ll paraphrase it because it’s a fair question that most people building with AI will eventually be asked: give me a date when the AI project makes this profitable. The specific project was a quiz funnel: answer a few questions, get a result, get marketed to. The premise behind the question was that the AI was the engine of monetization. Point it at the problem, and money comes out the other end on a schedule.
That isn’t what this is, and the gap between what it is and what it was being asked to be is the whole reason the architecture looks the way it does.
Here is the argument I made, and still make. A language model is a force multiplier on top of a domain expert’s knowledge. It is unreliable at generating that expertise in a fast-moving commercial domain, and quiz-funnel monetization is that kind of domain. Three reasons, and none of them are about the model being weak.
First, without an expert supplying the “what” and the “why,” a model defaults to the statistical center of its training data. In a specialized field, the statistical center is generic, entry-level output. It’s the advice that’s true, published everywhere, and therefore worth nothing as an edge.
Second, training data lags reality. Even with web access, a model can only retrieve what’s been written down, and by the time a winning tactic is widely written about, its edge is gone. You’d be optimizing toward last year’s playbook with great confidence.
Third, and most decisive: the playbooks that actually work are proprietary and stay that way. Nobody running a profitable funnel publishes their structures, their costs, their conversion rates. What’s public is content marketing: agencies writing blog posts to attract clients, sharing the version of the strategy that’s safe to give away. “Interrogate the model for the best quiz expert in the world” surfaces that public layer, confidently, and calls it expertise. This isn’t only my read. It’s the consistent message from people who study this for a living. Hamel Husain, Andrej Karpathy, and Ethan Mollick all land in the same place. The pattern that works is expert plus AI, not AI instead of expert.
So here is what codex actually is. It’s a knowledge layer, not an oracle. It’s the machine that takes a domain expert’s grounding and makes it compound: captured once, kept current, searchable, and applied consistently. Every decision in this article serves that and only that. The librarian is an agent because the value is in connecting an expert’s pages, not in reciting one. The maintainer runs the real skills because keeping the knowledge current is the entire job. The writes are sandboxed because a knowledge layer is only worth building if it can be trusted not to corrupt itself. None of it makes the model smarter. All of it makes a real expert’s knowledge go further.
Which means the honest measure of this system isn’t whether the AI made the quizzes profitable. It’s whether, when we put a real expert’s knowledge into the wiki, the team could act on that knowledge faster and more consistently than they could without it. That’s a question the architecture can answer yes to. The other question, the one about a date, was never the model’s to answer. It was always going to need an expert.
Where the value actually is
Step back from the individual decisions, and the shape is the point.
Knowledge compounds here instead of resetting. A question asked today doesn’t start where the same question started last month. It starts from a wiki that has already absorbed everything that arrived since. The expensive work, reading a source, placing it among the others, reconciling it with what’s already known, happens once, when the source lands, not again on every query. Over months that’s the gap between a system that plateaus and one that keeps getting sharper while I do nothing to it.
It stays current without me. The upkeep that keeps a knowledge base from rotting, folding in new material, fixing broken links, catching two pages that have drifted into contradiction, is exactly the work nobody has time to do by hand, so in most systems it quietly never happens. Here a model does it every morning. And because it runs the same skills I’d run myself rather than a reimplementation of them, the maintenance is as good as my own habits, not a thinner automated echo of them. I improve a skill on my laptop and the server inherits it on the next run.
The answers are checkable. The librarian searches like a researcher instead of fetching a single blob, so it connects what’s spread across pages and notices what isn’t there at all. It cites the page behind each claim, and when the wiki doesn’t have the answer it says so plainly instead of inventing one or going quiet. That last property is the whole game. A knowledge tool you can’t check is just a confident stranger.
And the thing that reads like a limitation is the actual design. The system is only ever as good as the expertise poured into the wiki, and that’s the feature, not the catch. Codex doesn’t manufacture knowledge. It compounds and circulates someone’s real knowledge: it carries a domain expert’s grounding to the whole team, keeps it current, and has it ready at the moment someone needs it. The model was never the asset. The maintained, expert-fed wiki is. The model is just the thing that keeps it alive, every morning, while no one is watching.
Jorge Garcia is a Lead AI Engineer building multi-agent systems in production. This is the third article in a series on the architecture decisions behind real LLM products.