
Five decisions from building a multi-agent assistant (and what the next version changes)
What I learned building Carolina, a LangGraph orchestration platform for a wellness company, including the part where the platform's content filter refused to let people talk about their feelings.

The product was a chatbot for a wellness company. Its job included talking with people about anxiety, trauma, and whether therapy could help them. The platform I built it on had other ideas. Azure’s content filter kept blocking the conversations mid-sentence, because someone describing their own pain looks, to a safety classifier, a lot like content that should be refused. I spent days engineering around that filter. Then I stopped, and moved the whole conversational layer somewhere else.
This article is about that decision and four others like it. It is not a tutorial. It is a record of how I reasoned under real constraints, what I got right, and what the next version of the system changes. I think that second part matters more than the first.
What Carolina is
Carolina is a conversational assistant I built as Lead AI Engineer for a wellness company. It runs over SMS and WhatsApp and wears several hats in the same conversation: it answers questions about the company’s practitioner training programs, talks with people who want therapy for themselves, matches them with a practitioner, books discovery calls against a real calendar, and hands off billing problems to customer support.
Under the hood it is an Azure Functions app running a LangGraph state machine. Eighteen specialized agents sit behind a supervisor that decides, every turn, who should speak. Conversation state is checkpointed to Postgres per thread, retrieval runs on Azure AI Search across the company’s knowledge bases, the practitioner directory, and the product catalog, and bookings go through the company’s CRM and calendar APIs. Telemetry streams to Azure Event Hub, partitioned by conversation thread so events stay ordered.
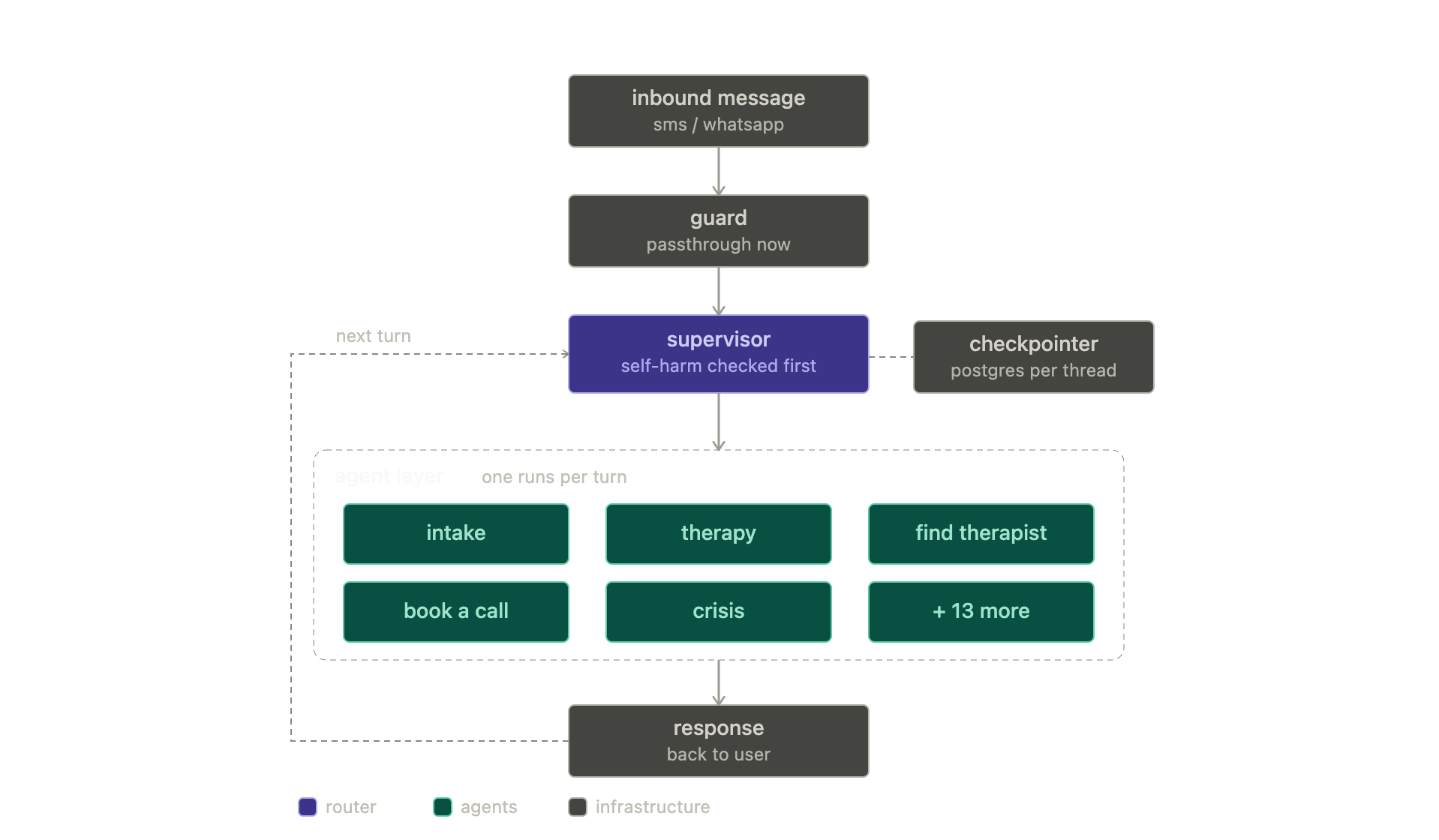
Decision 1: A supervisor, because people don’t follow funnels
My first instinct was the obvious one: define the user paths and build a flow for each. Someone asks about training, you qualify them, you offer a call, you book it. Clean.
Real conversations refused to cooperate. A person asking about the certification program would mention, three messages in, that actually they were struggling themselves and maybe needed help before a career change. Someone halfway through picking a call slot would say something that signaled self-harm. A fixed route has no answer for either. You can’t bolt an escape hatch onto every node of every flow; because that’s just a graph with extra steps, except you built it by hand.
So I made the routing itself a reasoning task. Every turn, a supervisor model reads the last few messages plus the name of the currently active agent and decides: stay, or hand off. The system prompt encodes the legal transitions between agents, and one rule sits above all of them: if the user shows any sign of self-harm, route to the crisis agent immediately, no matter what else is happening. The supervisor runs before any specialist gets to speak, so there is no path through the system that skips that check.
The cost is real: an extra model call on every single turn, spent purely on deciding who talks. I paid it because the alternative was a system that performs fine in demos and fails the one conversation where failing is not acceptable.
Decision 2: Fighting the content filter, then leaving
Everything ran on Azure OpenAI at first. It was the natural choice; the company’s whole stack is Azure. Then the content filter started killing conversations.
Azure AI Foundry applies content filtering you cannot fully turn off, and it judges the entire conversation history, not just the newest message. For most products that’s a sensible default. For a chatbot whose purpose includes letting people describe the worst things they are living through, it is fatal. A user would open up, exactly as designed, and a few turns later every model call would come back blocked, because the accumulated history now read as policy-violating content. The bot would go silent on someone mid-disclosure.
My first response was to engineer around it. I wrote a wrapper that catches the filter error and retries with progressively less history:
# Progressive truncation: full history -> last 5 -> last 1
truncation_strategies = [None, 5, 1]
for attempt in range(self.max_retries):
keep = truncation_strategies[attempt]
msgs = messages if keep is None else messages[-keep:]
try:
return self.llm.invoke({**input, "messages": msgs})
except BadRequestError as e:
if "content_filter" not in str(e).lower():
raise
# Every attempt was filtered. Say something safe instead of crashing.
return AIMessage(content="I'm here to help. What would you like to know?")It worked, in the sense that the bot stopped going silent. But look at what it actually does: when the conversation gets heavy, the assistant quietly forgets it. The user has spent ten minutes explaining their situation and the model is now answering with one message of context. Calling that a fix would be generous. The system abandons people at exactly the moment it was built for.
After days of this I accepted that the problem was not my retry logic. It was the platform. I moved the conversational layer to open-weights models served by Cerebras, where I control the safety behavior instead of renting someone else’s. The wrapper is still in the codebase, and I keep it there deliberately: it marks the difference between working around a constraint and recognizing that the constraint is the decision.
That choice came with a bill. Leaving the managed platform means the safety net is now mine to build, which is what Decision 4 is about.
Decision 3: One model per agent, not one model for everything
The migration forced a question I should have asked earlier: which model does each agent actually need?
I had been treating “the model” as a global setting. But GPT-5-mini, which I started with, was wrong for most of Carolina’s turns in two distinct ways. It was slow, and on a messaging channel the user is staring at a typing indicator the whole time. And it was conversationally dry. A person telling you they can’t sleep because of their divorce does not need a model that answers like documentation.
The graph structure made the fix natural, because model choice becomes a per-node decision:
Chatty, empathetic agents (intake, therapy, the crisis agent, goodbye) run Qwen 235B on Cerebras. Inference is fast enough that replies feel like texting a person, and the tone is warmer out of the box.
Tool-heavy agents (booking, therapist search) stayed on GPT-5-mini through Azure. Picking the right calendar slot tool with the right arguments is a precision problem, and I trusted it more there.
The supervisor runs gpt-oss-120b with high reasoning effort at temperature 0.1, because routing is a reasoning problem where creativity is a bug.
The general lesson: “one model for everything” is the absence of an architecture decision. Once routing is explicit, you can match cost, latency, and temperament to each job. The commit history of this project reads like a diary of me learning that, one model at a time.
Decision 4: Safety as routing, not filtering
The original design had a guard node in front of everything: every inbound message went through Azure’s content safety classifier, and flagged messages got a canned response before the graph even ran.
After leaving Foundry, I rebuilt safety around a different idea: detection through routing. The supervisor’s first instruction, evaluated before any routing logic, is to check for self-harm signals. If they appear, the conversation goes to a dedicated crisis agent whose prompt is short and strict: acknowledge the pain, never probe for details or methods, and always call the tool that retrieves crisis helpline resources, so the response contains a real link, not just sympathetic words. Because the supervisor sees every turn, this check cannot be bypassed by being three steps deep in a booking flow.
There is a real tradeoff here and it deserves to be stated plainly. Azure’s classifier checked for many categories of harmful content; my supervisor check really only watches for self-harm, which was the category that mattered most for this product. That narrowing bought lower latency on every turn, and it stopped the false positives that were blocking the conversations the product exists to have. Safety moved from a wall at the door to a person in the room.
That narrowing also gave something up, which is why the next version puts it back. The plan is to keep the supervisor’s self-harm check and add a second, lightweight classifier for the categories it doesn’t watch. The important part is how that classifier gets built: configured by me for a mental health context, not pulled generic off the shelf. That distinction is the whole reason Azure failed me in the first place. Its filter was built for every customer at once, so it couldn’t tell the difference between a person disclosing pain they had survived and content that should actually be refused. A classifier I set the thresholds on can be taught that line, because I know what my product is for and a default doesn’t. The right answer is probably both: routing for the case that can never be missed, and a tuned classifier for the rest.
Decision 5: Splitting empathy from search
At first, one therapy agent did two jobs: listen to the person, and search the practitioner directory when they were ready. It did both badly in a specific way. Mid-conversation tool calls kept breaking the empathy. The user would still be explaining their situation and the agent, eager to be useful, would jump to search results. Timing that a human gets intuitively turned out to be hard to prompt into a single agent doing two jobs.
So I split it. The therapy agent now has no tools at all. It can only listen, explore, and offer. The search lives in a separate find_therapist agent, and the supervisor only hands over when the user actually says yes or volunteers their location. The handoff itself becomes the consent moment.
Inside the search there is one piece of product reasoning I got after a back and forth with the CMO and product owner: expertise comes before geography. If you want to stop smoking, you want the practitioner who is the best in the world at smoking cessation, even if she is in another country; sessions are online anyway. So the agent searches by specialty first and treats location as a filter, not the other way around. That ordering came from asking what I would want as the person on the other end, not from what was convenient for the data model. It costs nothing extra to build and it is the kind of decision no framework makes for you.
What the next version changes
This is the section I most wanted to write, because the gap between the engineer who built the first version of Carolina and the one writing this now is what the article is really about.
Routing decisions used to be parsed as free text. The supervisor used to answer in a homemade protocol, “ROUTE: agent_name” or “STAY”, and I parsed it with string splitting plus a fallback that scanned the reply for agent names as substrings. It worked most of the time, which is the most dangerous amount of working. Rereading it while preparing this article, I winced, so I fixed it before publishing. The supervisor now returns structured output against a schema:
class RouteDecision(BaseModel):
reasoning: str
next_agent: Literal["STAY", "intake", "therapy",
"find_therapist", "book_a_call", ...]
decision = supervisor_llm.with_structured_output(RouteDecision).invoke(context)No parsing, no substring guessing, and an invalid answer raises instead of silently routing somewhere weird. The deeper lesson is about defaults again: when I first built this, I reached for text parsing because that’s what the examples did. Today, constrained output is the obvious tool. Writing the retrospective is what made me actually look.
The biggest item on the roadmap is an eval harness. My git history is full of commits that say “updated prompt for supervisor.” Each one was me reading a conversation that went wrong, adjusting the routing prompt, and trying again. That is an evaluation loop running on vibes. Routing is the most testable thing in the entire system: a set of conversation snippets and the agent each should route to is just a labeled dataset, and I was generating those labels by hand every time I read a transcript. With that harness, every prompt change becomes a measurable diff instead of a hopeful one. The next version starts with the first twenty routing test cases before a single new agent gets added.
Two smaller items sit behind it. Prompts currently live as Python string constants, which means a prompt change is a code deploy and there is no clean way to diff behavior across versions; moving them into versioned, structured config is next. And while telemetry already flows to Event Hub and traces to LangSmith, the dashboard that answers the first question any stakeholder asks, where do conversations actually go and where do they stall, is the piece I’d build on top of that data.
What I’d tell you to take from this
Carolina taught me that the expensive constraints in an LLM product are rarely the ones you planned for. I budgeted my attention for routing logic and conversation design. The thing that nearly sank the product was a content filter, and the thing that would save the most time going forward is a test set, which is exactly why it sits at the top of the list.
If you are building something similar, the one habit I’d push you toward is writing down why you chose things, at the moment you choose them. Half of this article was reconstructed from my own commit messages. The half I could reconstruct made me a better engineer the second time through. The half I couldn’t is just gone.
Jorge Garcia is a Lead AI Engineer building multi-agent systems in production. This is the first article in a series on the architecture decisions behind real LLM products.